-
[프로그래머스] 전화번호 목록 # HashAlgorithm 2024. 9. 8. 01:19

문제 링크
1. 문제 설명
전화번호를 담은 배열 phone_book이 파라미터로 주어질 때, 전화번호부에 적힌 전화번호 중 한 번호가 다른 번호의 접두어인 경우가 있으면 False를, 그렇지 않으면 True를 반환한다.
2. 제한 사항
- 1 <= phone_book <= 1,000,000
- 1 <= phone_book에 담긴 전화번호 각 길이 <= 20
- 같은 전화번호가 중복해서 들어있지 않음
3. 입출력 예

4. 첫 번째 풀이(시간 초과) - Python
냅다 for문 두 번 돌려버렸다. 이중 중첩 반복문을 순회하면서 현재 전화번호가 비교 대상 전화번호와 다르고, 자신의 전화번호가 비교 대상 전화번호로 시작하는지 판단한다.
리스트를 동시에 두 번 조회하므로 시간복잡도 O(n^2)이다. 그리고 현재 전화번호가 비교 대상 전화번호와 다른지 판단해야한다는 의미는 자기 자신과의 비교를 불필요하게 수행하고 있다는 의미이다. 당연히 시간초과 발생..
def solution(phone_book): answer = True for i in phone_book: # O(n) for j in phone_book: # O(n) if j != i and j.startswith(i): answer = False return answer
5. 두 번째 풀이 - Python
list 조회에 대한 시간복잡도는 O(n)이지만 set 조회에 대한 시간복잡도는 O(1)이다. 파이썬 set은 조회 시간복잡도 O(1)인 해시테이블 기반으로 구현되어있기 때문이다. 따라서 list인 phone_book을 set으로 형변환을 해준다. 그리고 phone_book을 순회하면서 각 번호로 prefix를 만든다. prefix는 자기 자신의 번호를 [:1]부터 [:2], [:3], ... [:len(phone_number) - 1] 까지 슬라이싱해서 만들고, 해당 prefix가 phone_book의 요소라면 False를 반환한다.
첫 번째 풀이와 비교해서 list를 set으로 변경했고, 모든 전화번호를 서로 비교하는 방식(O(n * n))에서 자신의 전화번호와 자신의 전화번호로 만든 접두어를 비교하는 방식(O(n * 1))으로 개선했다. 만약 set가 아닌 list를 그대로 사용했다면 if prefix in phone_book: 에서 O(1)이 아닌 O(n)의 시간복잡도가 소요됐을 것이다.
def solution(phone_book): phone_book = set(phone_book) # 조회 시간복잡도를 O(1)로 만들기 위해서 해시 기반의 set 자료형으로 변환 answer = True for phone_number in phone_book: # O(n) for i in range(1, len(phone_number)): # O(19) -> O(1) prefix = phone_number[:i] if prefix in phone_book: # O(1) return False return True
6. 세 번째 풀이 - Python
세 번째 풀이에서는 정렬 후 인접한 번호끼리만 정렬한다. 정렬하게 되면 이전 전화번호가 자신의 접두어인지만 판단하면 되기 때문이다. 이 풀이의 시간복잡도는 O(n log n)이다. 실제로 측정해보니 두 번째 풀이의 효율성과 거의 3~4배 차이가 난다. 역시 단순 개선으로는 부족하고 생각의 패러다임 자체를 바꿔야 한다.
def solution(phone_book): answer = True phone_book.sort() # 인접한 번호끼리만 비교하기 위해 정렬 for i in range(len(phone_book) - 1): # i + 1로 조회하기 위해 순회 범위는 phone_book 길이의 -1까지로 잡는다 if phone_book[i+1].startswith(phone_book[i]): answer = False return answer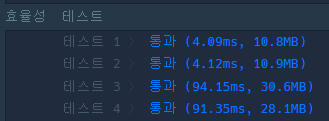
7. 네 번째 풀이 - Python
Trie 자료구조를 사용해서 풀 수도 있다. 일반적으로 Trie는 문자열 검색에 최적화된 자료구조이지만, 메모리 사용량이 많고 데이터량이 적거나 공통의 prefix가 거의 없는 경우 오히려 비효율적일 수 있다. 이 문제는 데이터량은 많지만 공통의 prefix가 많다는 보장이 없기 때문에 트라이 사용이 이 문제의 최적화 방안은 아닌 것 같지만 한 번 적용해보고 싶었다. 시간복잡도 측정 결과 예상은 했지만 두번째, 세번째 풀이와 비교했을 때 가장 비효율적이다.
Trie를 구현하기 위해서는 insert 이외에도 search 메소드 , starts_with 메소드를 구현해야 하는데, 이 문제에서는 prefix가 있는지만 판단하면 되기 때문에 현재 노드가 단어의 끝을 의미하는 경우(이미 존재하는 접두어인 경우) False를 반환하는 insert 메소드만 구현했다. 참고로 search 메소드는 마지막 노드에 data가 존재하면 True, 존재하지 않거나 자식노드가 없다면 False 반환하고, starts_with 메소드는 prefix로 시작하는 단어들을 배열로 반환한다.
class TrieNode: def __init__(self): self.children = {} self.is_end = False class Trie: def __init__(self): self.root = TrieNode() def insert(self, word): """ 새로운 노드 생성 """ node = self.root # 루트에서 시작 for char in word: # 입력받은 단어의 각 문자를 순회 if char not in node.children: # 현재 노드의 자식에 해당 문자가 없다면 node.children[char] = TrieNode() # 새로운 노드를 생성해서 해당 문자의 자식으로 추가 node = node.children[char] # 자식 노드로 이동 if node.is_end: # 현재 노드가 단어의 끝일 경우(이미 존재하는 접두어인 경우) return False node.is_end = True # 마지막 노드를 단어의 끝으로 표시 return True # 새로운 노드 삽입 성공 def solution(phone_book): trie = Trie() for phone_number in sorted(phone_book, key=len): if not trie.insert(phone_number): return False return True
8. 다섯번째 풀이 - Java
세 번째 풀이를 자바로 풀어봤다.
import java.util.Arrays; class Solution { public boolean solution(String[] phone_book) { Arrays.sort(phone_book); boolean answer = true; for (int i = 1; i < phone_book.length; i++) { if (phone_book[i].startsWith(phone_book[i-1])) { answer = false; } } return answer; } }9. 새롭게 알게 된 점
- 두 번째 풀이에서 set의 조회 시간복잡도가 O(1)이라고 했는데, 이는 일반적인 상황인 것이고 해시 함수 성능이 모든 키에 대해서 같은 해시값을 반환하는 최악의 경우에는 O(n)이 소요될 수 있다.
- startswith() 메소드의 시간 복잡도는 O(n)이다.
- 트라이는 자동 완성, 사전 구현, IP 라우팅같이 여러 문자열에서 공통 접두어를 빠르게 찾아야 할 때 특히 유용하다.
'Algorithm' 카테고리의 다른 글
[프로그래머스] - 괄호 회전하기 # Stack (0) 2024.09.09 [LeetCode] 436. Find Right Interval # Binary Search (0) 2024.09.08 99클럽(3기) - 코테스터디 9일차 TIL # DP (0) 2024.08.13 99클럽(3기) - 코테스터디 6일차 TIL # 이분탐색 (0) 2024.08.04 99클럽(3기) - 코테스터디 5일차 TIL # 이분탐색 (0) 2024.08.04